쿼리를 짜다보면 Slow Query에 부딪히는 경우가 생긴다.
데이터가 쌓일수록 점점 느려지는 쿼리를 개선해야 하는데 어떻게 해야할까?
EXPLAIN 명령어를 통해서 데이터베이스 옵티마이저의 실행계획을 볼 수 있다.
EXPLAIN
SELECT * FROM test
MySQL은 내가 알기로는 표 모양으로 실행 계획을 보여준다.
다른 SQL 또한 비슷하게 잘 보여주는 것으로 안다.
하지만 PostgreSQL은 텍스트로 실행계획을 보여주기 때문에 실행계획을 파악하기가 좀 힘들다.
그래서 PostgreSQL을 사용하는 개발자라면 이 사이트를 추천한다.
explain.dalibo.com
explain.dalibo.com
쿼리문 앞에 EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS, FORMAT JSON)을 붙여서 실행시키면 실행계획을 JSON으로 얻을 수 있는데 실행계획 JSON을 Plan에, 실행쿼리는 밑의 Query에 붙여넣어주고 Submit을 눌러주면 된다.
실행계획을 확인하기 전에 주의할 점이 있다.
데이터베이스마다, 그리고 데이터베이스의 버전마다 사용하는 옵티마이저가 다를 수 있다.
본인이 사용하는 옵티마이저가 규칙기반인지 비용기반인지 잘 확인하고 최적화를 진행해야 한다.
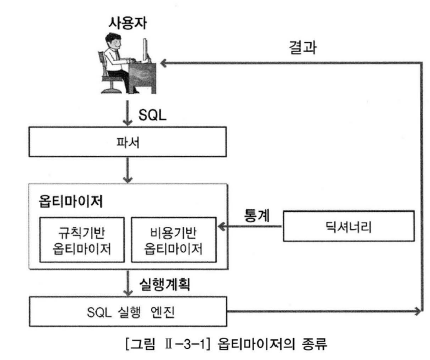
최적화를 하기 위해 주의해야 할 것이 몇 가지 있는데 내가 아는대로 써보자면 다음과 같다.
- WHERE 절에는 가능하면 인덱스를 타도록 해주자
where절에 인덱스 값으로 조건을 줘도 인덱스를 타지 않는 경우가 있다.
WHERE TO_CHAR(user_id) = '1'와 같이 좌변을 가공하면 인덱스를 타지 않는다.
user_id가 number형인데도 WHERE user_id = '1'처럼 묵시적 형변환을 하게 만드는 것 또한 지양해야 한다.
- 인덱스에 연산자를 사용할 때는 가능하면 =을 사용하자
LIKE, IN, IS NULL, 부정연산자 등은 인덱스 효율이 떨어진다.
심지어 인덱스를 타지 않는 경우도 있다.
- OR 보다는 AND를 사용하자
OR는 옵티마이저에서 UNION ALL로 변환한다.
가능하면 AND를 사용할 수 있도록 쿼리를 변경해주자.
- IN 대신 EXISTS를 사용하자
IN은 모든 집합에서 조건에 해당하는 집합을 찾는다.
EXISTS는 조건에 맞는 단일행을 찾기 때문에 성능면에서 유리하다.
- JOIN 순서를 잘 정하자
JOIN은 데이터의 수가 작은 것부터 작성해주는 것이 좋다.
- 정 안되겠으면 힌트를 사용하자
힌트를 이용해서 어떤 인덱스를 타는지 등등 여러가지를 지정해줄 수 있다.
이 정도만 지켜도 쿼리가 느려지는 경우를 어느정도 방지할 수 있다.
주의할 점은 인덱스를 사용하면 여러 이점이 있지만, 그렇다고 인덱스를 남용하면 안된다.
인덱스가 너무 많아지면, 옵티마이저가 풀스캐하는이 더 낫다고 판단하여 인덱스를 타지 않는 경우가 생길 수 있기 때문이다.
가능하면 인덱스를 생성하기보다는 SQL문을 최적화하고, 그럼에도 성능 개선이 더 필요하면 그 때 인덱스 생성을 생각해보자.